分组及引用:
\(string\) :将string作为一个整体方便后面引用
\1 :引用第1个左括号及其对应的右括号所匹配的内容。
\2 :引用第2个左括号及其对应的右括号所匹配的内容。
\n :引用第n个左括号及其对应的右括号所匹配的内容。

3、扩展的(Extend)正则表达式(注意要使用扩展的正则表达式要加-E选项,或者直接使用egrep):
匹配字符:这部分和基本正则表达式一样
匹配次数:
* :和基本正则表达式一样
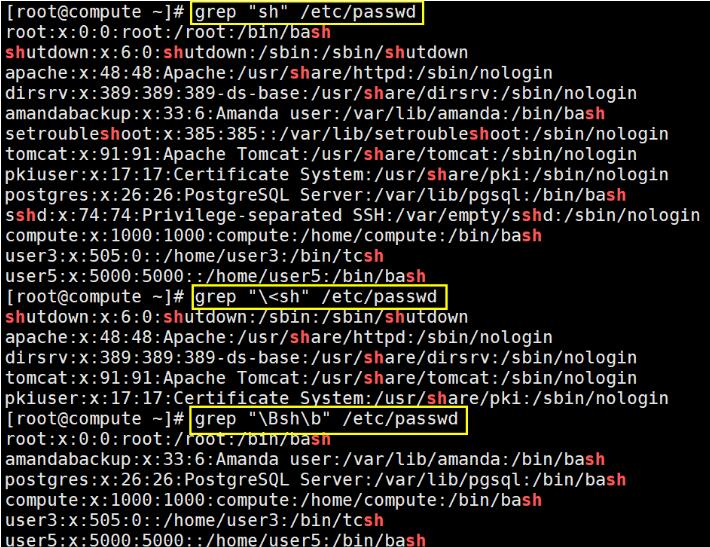
? :基本正则表达式是\?,二这里没有\。
{m,n} :相比基本正则表达式也是没有了\。
+ :匹配其前面的字符至少一次,相当于{1,}。
位置锚定:和基本正则表达式一样。
分组及引用:
(string) :相比基本正则表达式也是没有了\。
\1 :引用部分和基本正则表达式一样。
\n :引用部分和基本正则表达式一样。
或者:
a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。
注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 “a.*b” 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。