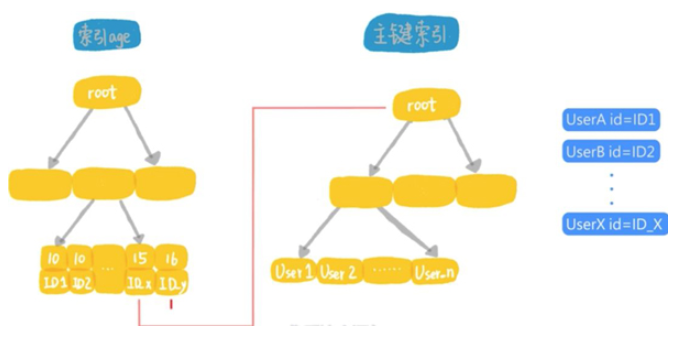
这个语句的执行流程是这样的:
从索引上用树搜索,取到第1个age等于10的记录,得到它的主键id的值,根据id的值去主键索引取整行的信息,作为结果集的一部分返回;
在索引age上向右扫描,取下一个id的值,到主键索引上取整行信息,作为结果集的一部分返回;
重复上面的步骤,直到碰到第1个age大于15的记录;
你看这个语句,虽然他用了索引,但是他扫描超过了1亿行。所以你现在知道了,当我们在讨论有没有使用索引的时候,其实我们关心的是扫描行数。
对于一个大表,不止要有索引,索引的过滤性还要足够好。
像刚才这个例子的age,它的过滤性就不够好,在设计表结构的时候,我们要让所有的过滤性足够好,也就是区分度足够高。
回表的代价
那么过滤性好了,是不是表示查询的扫描行数就一定少呢?
我们再来看一个例子:
如果你的执行语句是 select * from t_people where name=‘张三’ and age=8
t_people表上有一个索引是姓名和年龄的联合索引,那这个联合索引的过滤性应该不错,可以在联合索引上快速找到第1个姓名是张三,并且年龄是8的小朋友,当然这样的小朋友应该不多,因此向右扫描的行数很少,查询效率就很高。
但是查询的过滤性和索引的过滤性可不一定是一样的,如果现在你的需求是查出所有名字的第1个字是张,并且年龄是8岁的所有小朋友,你的语句会怎么写呢?
你的语句要怎么写?很显然你会这么写:select * from t_people where name like ‘张%’ and age=8;
在MySQL5.5和之前的版本中,这个语句的执行流程是这样的: