虚拟列
可以看到这个优化的效果还是很不错的,但是这个优化还是没有绕开最左前缀原则的限制,因此在联合索引你还是要扫描8000万行,那有没有更进一步的优化方法呢?
我们可以考虑把名字的第一个字和age来做一个联合索引。这里可以使用MySQL5.7引入的虚拟列来实现。对应的修改表结构的SQL语句:
alter table t_people add name_first varchar(2) generated (left(name,1)),add index(name_first,age);
我们来看这个SQL语句的执行效果:
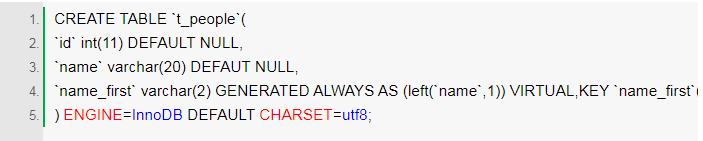
首先他在people上创建一个字段叫name_first的虚拟列,然后给name_first和age上创建一个联合索引,并且,让这个虚拟列的值总是等于name字段的前两个字节,虚拟列在插入数据的时候不能指定值,在更新的时候也不能主动修改,它的值会根据定义自动生成,在name字段修改的时候也会自动修改。
有了这个新的联合索引,我们在找名字的第1个字是张,并且年龄为8的小朋友的时候,这个SQL语句就可以这么写:select * from t_people where name_first=‘张’ and age=8。
这样这个语句的执行过程,就只需要扫描联合索引的100万行,并回表100万次,这个优化的本质是我们创建了一个更紧凑的索引,来加速了查询的过程。
总结
本文给你介绍了索引的基本结构和一些查询优化的基本思路,你现在知道了,使用索引的语句也有可能是慢查询,我们的查询优化的过程,往往就是减少扫描行数的过程。
慢查询归纳起来大概有这么几种情况:
全表扫描
全索引扫描
索引过滤性不好