但硬软件开发造价无疑是阻碍普及的重要因素,本系统采用ARM Cortex M3 内核ST 公司的32 位高性能单片机STM32F103C8T6结合LD3320语音识别芯片,通过构建SD卡文件系统实现非特定人语音识别关键词动态编辑功能,适用于嵌入式语音识别场合。系统电路简单,性价比高,识别距离和识别精度都可以满足嵌入式应用。
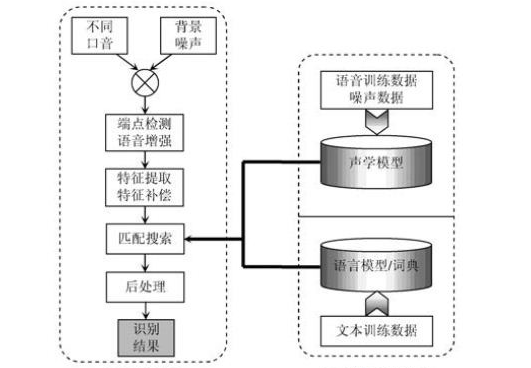
非特定人语音识别技术研究的最终目的是让计算机等设备能够“听懂”人类语音,提取出语音中所包含的特定信息,成为人机通信和交互最便捷的手段。由于语音信号本身具有不确定性、动态性和连续性,这就为准确量化和处理该信号带来非常大的困难,每个人的语音要建立不同的语音样本也为识别的普及带来瓶颈约束。目前的语音识别是先建立特征库然后将待识别的信号经处理与特征库比对得到相似结果判定输出。从本质上属于基于统计模式的基本理论,分语言模型训练、识别分析两个大阶段构成和实现。
声学训练阶段通常是离线完成的,由语言学家对预先收集好的海量语音样本、语言数据库、噪声数据进行信号处理和知识挖掘,通过语音信号处理理论及相应数学算法模型建立语音识别系统所需要的“声学模型”和“语言模型”.
识别分析阶段通常是在线完成的,对用户实时的语音进行自动识别。识别过程通常又可以分为“前端”和“后端”两大模块:“前端”模块主要的作用是进行端点检测、降噪、特征提取等;“后端”模块的作用是利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别,得到其包含的文字信息,此外,后端模块还存在一个“自适应”的反馈模块,可以对用户的语音进行自学习,从而对“声学模型”和“语音模型”进行必要的“校正”,进一步提高识别的准确率。