GPC+=4;
virt_addr2=map_base+0x824;//配置观察IO
GLEDstate=*(volatile unsigned int *)(virt_addr2);
}
void Init_Timer(){ //添加加配置1微秒时基定时器
int fbb;
unsigned int temp;
fbb=open(“/dev/mem”,O_RDWR | O_SYNC);
map_base=(char *)mmap(0,4096,PROT_READ|PROT_WRITE,MAP_SHARED,fbb,0x7f006000);
…………………… 篇幅原因略去部分次要代码
MYSYSTICK=map_base+0x14;
}
void SPI_init(){
bits=8;
speed = 16625000;
trr.len =20;
trr.delay_usecs = 0;
trr.speed_hz = speed;
trr.bits_per_word = bits;
fspi = open(“/dev/spidev0.0”, O_RDWR);
ioctl(fspi, SPI_IOC_RD_MODE, &mode);
ioctl(fspi, SPI_IOC_WR_MODE, &mode);
}
__inline unsigned int GETSYSCLK(){
return(*(volatile unsigned int *)(MYSYSTICK));
}
__inline void CSFPGAL(){
map_GPC&=0xfffffff7;
*(volatile unsigned int *)(GPC)=map_GPC;
}
__inline void CSFPGAH(){
map_GPC|=0x00000008;
*(volatile unsigned int *)(GPC)=map_GPC;
}
void test(){
GLEDstate&=0xfffffffe;
*(volatile unsigned int *)(virt_addr2)=GLEDstate;//产生GPIO负跳变
starttime2=GETSYSCLK();
*(volatile unsigned int *)(FPGA_RUN-0x0c)=0x00;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x23;
*(volatile unsigned int *)(FPGA_RUN-0x18)=0x03;
CSFPGAL();
*(volatile unsigned int *)(FPGA_RUN)=tx[0];
*(volatile unsigned int *)(FPGA_RUN)=tx[1];
*(volatile unsigned int *)(FPGA_RUN)=tx[2];
*(volatile unsigned int *)(FPGA_RUN)=tx[3];
*(volatile unsigned int *)(FPGA_RUN)=tx[4];
while (((*(volatile unsigned int *)(FPGA_RUN-4)&0xfe000)》》13)2000000){ //2000ms测试一次
waittime=GETSYSCLK();
test();
}
}
}
图1示波器截图添加了一些时间信息以便对应代码注释说明,对应于代码mmap方式和标准驱动调用方式产生了两组SCK时钟,GPIO观察脚显示第一次SPI访问消耗5μs,第二次访问消耗114μs,其中真正操作SPI的时间也就4μs不到,其它时间消耗在系统应用层到内核两次双向的数据拷贝以及为了统一对外接口所做的数据结构配置等方面,由此对比可以看出两种方式访问效率上的巨大差异。
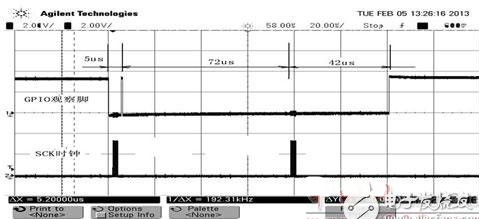
图 1
结语
通过mmap方式应用程序在Linux下操作硬件寄存器,适合于关注高效率的访问场合,在嵌入式应用中,我们既能够获得使用操作系统管理任务和丰富开源驱动库的好处,同时又能在局部提升处理效率,提高处理数据的实时性。