TDM模块设计
TDM模块一端的界面是多路音频信号的输入与输出,另一端是AHB总线,音频数据的输入/输出,通常采用帧结构TDM形式(见图1)。其中,sp_io_xclk代表音频数据采样时钟,sp_io_xfs代表帧同步头,下面两行分别是输出与输入数据。可见,这是一个含帧格式的多通道时分实时数据传输格式。关于AMBA总线,有大量介绍资料,此处不赘述。
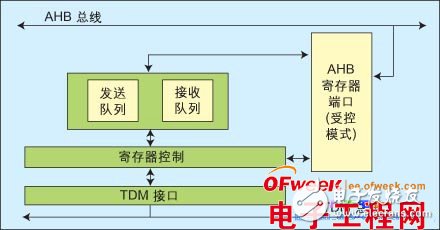
在这个模块的设计中,我们考虑了以下几个原则:平滑匹配数据传输速度、低延时与低资源占用(逻辑与存储资源)、高效使用AHB总线宽带、提高CPU处理效率、可靠性与错误处理、可控性与可观性。最基本的思路是:采用FIFO(先入先出)技术暨队列来缓冲数据传输,同时要尽量少缓存数据在队列中,以满足低延时与低资源的占用;同时采用AHB burst模式提高总线利用带宽;最后,还要提供寄存器读写来控制传输参数与状态存储,采用AHB从控模式(Slave)。初步的设计结构如图2。
DMA技术的使用时机
在这个初步设计中,缓存队列的长度计算主要取决于AHB burst的速度与频率。要少缓存数据,就要频繁进行AHB传递,也就是频繁中断CPU,这降低了CPU的处理效率。
这看起来是无解的矛盾,我们可以采用DMA(Direct Memory Access,直接存储读写)技术解决。一般SoC芯片都有外接DDR/SDRAM作为最终的数据与程序缓存,TDM模块可以直接向DRAM传输实时数据,而不用频繁地中断CPU,实质上是把片内缓存的需求转移到了片外(假设总线带宽足够),既降低了队列长度又降低了中断CPU的频率,从而解决了这一对矛盾。
DMA技术实质上也是模块主动掌握总线主动权,要求采用AHB总线主控模式,最终框架结构会变成图3所示。
延时与DMA应用的矛盾
细心的读者会发现DMA的采用增加了处理延时,这不是与我们的原则矛盾吗?这里牵涉到对嵌入式CPU中音频处理算法的理解,大多数是音频压缩算法,一般都要求有一定的音频片断长度以保障压缩率与减少CPU中RTOS的调度开销。另外一些音频处理程序如回响消减DSP算法,经常采用64拍有限滤波器处理大于16ms的回响拖尾。另一些高度压缩算法(如以有限激励参数模型为基础的算法)要求对更长的音频片断做处理。所以从算法的角度,SoC系统的音频处理延时理论下限为多算法处理单元的最大值。我们只要保证DMA的传输数据延时小于这个下限就可以了,这样就充分利用了SoC系统的最小延时,进而计算DMA片断的长度也有了依据。
回到队列长度的计算上,我们现在只需要考虑TDM模块得到AHB总线使用权之间的间隙与TDM数据输入的速度差的最坏值就可以了。