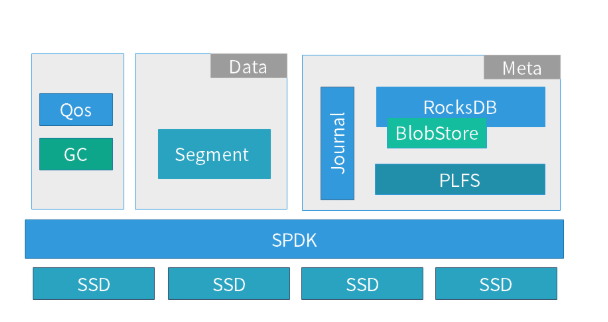
数据管理模块职责:
它是一个 segment 空间管理的基础单元,所有的数据都是以追加写入的,即底层的 SSD 都是顺序写入的,这样能够尽可能发挥每块 SSD 的性能,降低 SSD 本身 GC 带来的开销。
同时整个 store 的系统都是基于 SPDK 的中 spdk_thread 编程模型实现的,整个 IO 过程全部在一个独立线程中完成,所以不会有线程切换和锁的开销。
当然全异步的编程方式会导致开发的难度比较高,所以我们研发内部也提炼了一套基于状态机的异步编程方式,在各个子系统都采用一个子状态机,这样既保证了系统的高性能,也保证了系统的可维护性和可扩展性。
元数据管理模块职责:
对于元数据的存储,我们借鉴了 Ceph 中 BlueStore 的 Rocksdb 方式,也是采用一个简化的用户态文件系统 PLFS 来对接 Rocksdb。
而采用这样的方式,也是因为我们重点考查了 LSM 和 B-tree 的存储结构的不同及能够带来的收益,对于存储引擎中频繁的数据写入,相对简洁的元数据管理(本地存储引擎提供的对象存储接口,元数据层次是平铺的),采用 LSM 有利于提升系统写性能。
下面分别介绍一下本地存储引擎的技术特点。
元数据引擎技术特点:
使用自研 Journal,替换 RocksDB 的 WAL,这样元数据的修改都是增量地写入到 Journal 中,在后期定时刷盘时才写入到 RocksDB 中。 这个改进是基于下面几点方面的原因: a) PLStore 是全异步的编程模型,而 RocksDB 的接口是同步的,会阻塞整个 IO 路径,性能比较差。 b) Journal 的数据是增量更新的,这样能够实现聚合的方式写入,降低元数据写入次数。 c) Journal 不仅仅记录了 Object 的元数据更新,还承载了分布式一致性协议中的 LOG 功能(类似 Ceph 中的 PGLOG),而多个功能融合能够减少数据的写入次数。
改进 RocksDB 的 compact 处理,在数据聚合时在内存中建立一个基于 B-tree 的位置索引,这样在 RocksDB 的数据读取时,可以直接通过索引获得数据的位置信息,然后利用位置信息直接通过异步的数据读取口。 这样就将原有的 RocksDB 同步读接口改造成了异步,能够明显地提升单线程下的读取能力,通过实测有 5-8 倍的提升。
数据存储引擎技术特点:
对于数据使用追加写的方式,更加有利于发挥每块 SSD 性能,能够实现更加丰富的数据逻辑空间管理,为存储的一些高级特性,如快照、克隆、压缩重删的实现提供基础。
与此同时,使得我们需要在 store 层实现空间回收(GC),而空间回收的设计对提升追加写的存储系统性能和稳定性至关重要。