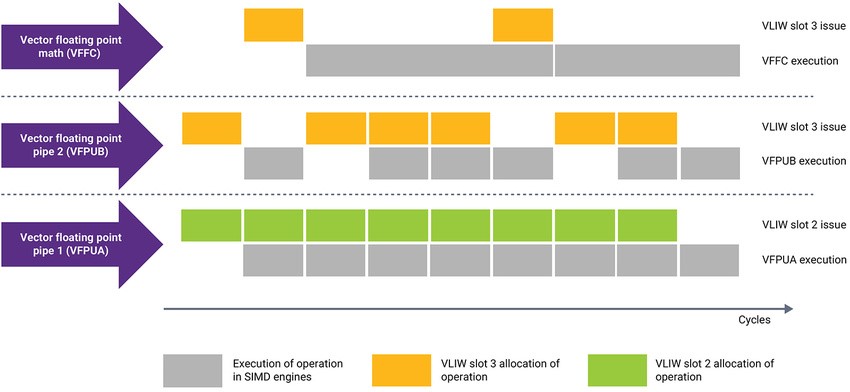
图 2:三个并行向量 FPU 执行的编译器分配
第 3 维度:可配置为单核、双核及四核
DesignWare ARC VPX5 处理器 IP 与多个向量 SIMD 计算引擎并行,并带有 VLIW 分配功能, 允许将单核扩展到双核和四核配置。这样可以根据需求将单核 VPX5 的计算性能提高一倍或三倍,以满足更高的计算需求。DesignWare ARC MetaWare 开发工具完全支持跨多核配置的代码编译和执行。此外,由于产品包含信号功能,所以可支持多核任务执行和同步。
对于单核、双核和四核配置,数据移动是 VPX5 产品的关键。有一个 2D 直接内存访问 (DMA) 引擎,可配置多达四个以上的通道,每个周期最多提供 512 位传输。DMA 可以在各个多核的数据存储器之间、本地集群存储器之间或在外部 AXI 总线的输入/输出之间并行移动数据。这种高性能 DMA 与 VPX5 处理器的高计算吞吐量相得益彰,使向量 SIMD 引擎可以不断访问每个内核上与本地紧密耦合的向量数据存储器中的新向量数据。
第 4 维度:线性代数计算
许多新一代算法使用依赖线性代数基本函数的数学方程式和计算来实现计算吞吐量。此类示例包括对象跟踪和识别、预测建模以及一些筛选操作。在这种新的驱动趋势之下,VPX 处理器在提供纯粹用于线性代数的专用向量 SIMD 浮点计算引擎方面独树一帜。该引擎硬件加速了线性功能,例如除法、SQRT、1/SQRT、log2(x)、2^x、正弦、余弦和反正切,并在 SIMD 向量中予以执行,从而提供了非常高的性能。
这对于性能数字有何影响?
借助四维度并行处理功能,DesignWare ARC VPX5 处理器 IP 可满足高吞吐量应用对浮点和线性代数处理的需求。与具有类似架构的其他 DSP 处理器相比,该方案提供了业界领先的性能指标 - 例如,配置最高的 VPX5 每周期可提供 512 次半精度浮点运算1.5GHz 运行,相当于 768 GFLOP。此外,ARC VPX5 根据线性代数运算的使用情况,每周期可提供 16 次数学浮点计算。对于机器学习计算算法中使用的 8 位整数数据,VPX5 每周期最多则可提供 512 个 MAC。