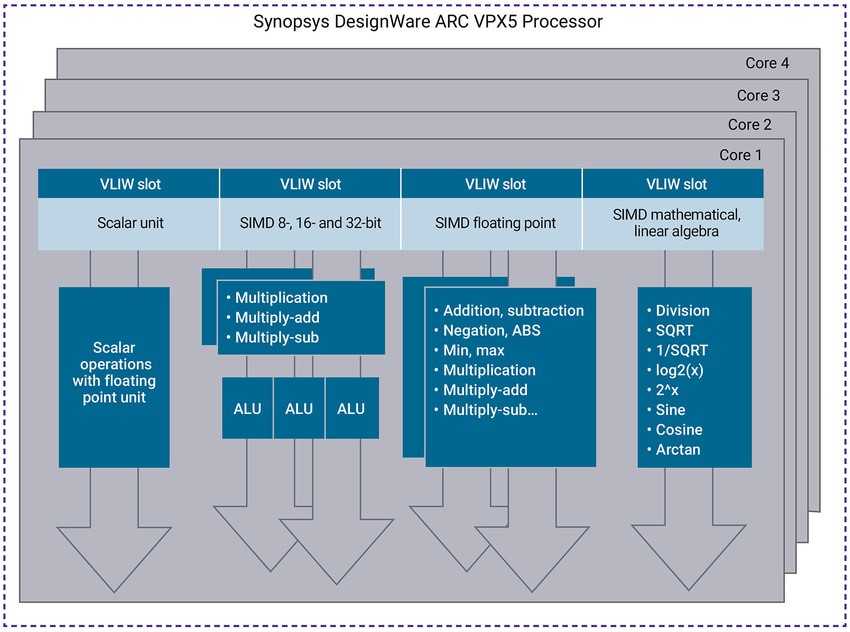
图 1:在 DesignWare ARC VPX5 处理器 IP 上并行执行的 4 个维度
第 1 维度:浮点的多 SIMD 计算引擎
基本向量数据长度为 512 位,从而可以对 8 位、16 位和 32 位数据,或半精度和单精度浮点数据的数据单元进行 SIMD 计算。所有 SIMD 引擎都使用 512 位向量长度进行计算;这就确定了 ARC VPX5 处理器的计算能力上限。
对于 8 位、16 位和 32 位长度的整数数据,有两个 512 位 SIMD 计算引擎以及三个 ALU 处理单元。这为机器学习卷积运算(5x5、3x3 和 1x1)等算法提供了非常高的计算水平。
对于半精度和单精度浮点计算,有三个向量 SIMD 计算引擎,所有引擎都支持 512 位的最大向量长度。用于“常规”浮点向量运算的双 SIMD 引擎,为包括FFT的DSP函数和矩阵运算等在内的浮点向量运算提供了超高性能。
第三向量 SIMD 浮点引擎专用于线性代数数学函数。这种专用引擎允许卸载和并行计算数学函数,将会在第 4 维度部分中进一步说明。
第 2维度:借助多任务发布 VLIW 实现灵活性
在 4 次发布 VLIW 方案中执行灵活分配,使处理器能够尽可能分配最多的并行操作。VLIW 方案的开发与软件编译器的开发工作实现了密切配合,因此编译器会预先分配在原始 C 代码程序中编译的运算符。编译器与 VLIW 架构相结合,可以跨多个 SIMD 引擎并行执行操作
例如,图 2 显示了编译器如何能够结合 VLIW 分配方案,仅使用两个 VLIW 插槽即可实现跨三个浮点 SIMD 引擎的并行执行,并且实现最佳的 VLIW 插槽分配和更小的指令代码大小。因为两个向量 SIMD 浮点引擎具有零周期插入延迟,所有可以在每个周期将向量数据加载到 SIMD 引擎中。线性代数向量 SIMD 引擎的插入延迟为四个周期,因此在加载数据之后,需要额外等待三个周期,直到可以加载新的向量数据为止。编译器可以为这种不同的插入延迟预先分配 VLIW 插槽,从而在所有三个向量 SIMD 浮点引擎上提供有效的并行执行。